Agent mode service overview
A deep dive into the architecture powering Agent Mode in Postman.
Agent Mode powers conversational workflows in Postman. Instead of navigating the UI manually, users can interact with Postman through natural language while an AI agent performs actions on their behalf.
Under the hood, this requires orchestrating large language models (LLMs), tool execution, conversation memory, and streaming responses — all while maintaining low latency and flexibility across model providers.
This post walks through the architecture of the Agent Mode Service, the backend responsible for powering this experience.
The Core Request Flow
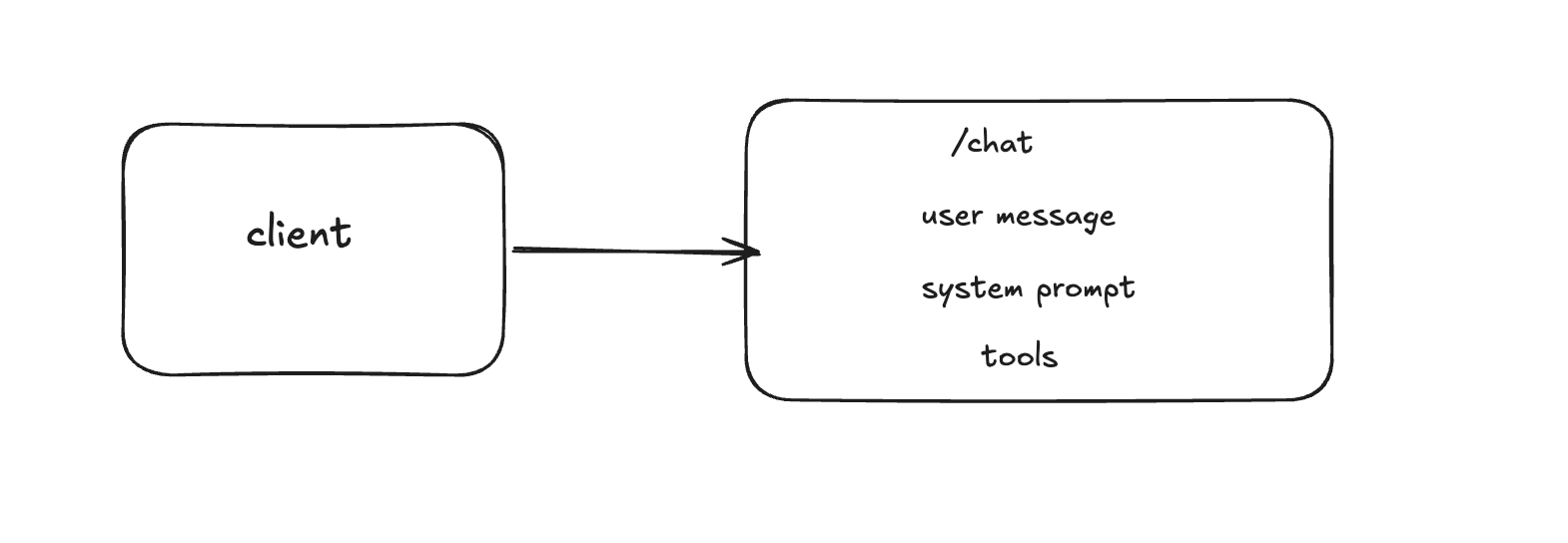
When a user submits a prompt, the client sends a request to the /chat endpoint of the Agent Mode Service.
The service prepares the request for the LLM by combining:
- the user prompt
- a system prompt
- a filtered list of tools available to the agent
The LLM can then respond in one of two ways:
- Assistant response – a natural language answer
- Tool call – an instruction to invoke one of the available tools
Once a tool executes, the result is returned to the LLM so it can continue reasoning and generate the final response.
The service also powers LLM-generated prompt suggestions, which add significant load to the system. However, for the purpose of this post we focus only on the /chat endpoint.
System Requirements
Before diving into the architecture, it's helpful to understand the key requirements the system needs to satisfy.
At the time of writing, the /chat endpoint receives roughly:
- 119 requests per minute on average
- 173 requests per minute at p90
These numbers are meaningful because every new user onboarding flow in the app starts with an Agent Mode prompt.
Beyond scale, the system must support several important capabilities.
Conversation Persistence
Users should be able to continue past conversations. This requires reliably storing the full conversation history.
Large Tool Ecosystem
Agent Mode can perform most actions available in the Postman UI. As a result, the system currently exposes 150+ tools to the LLM.
Passing all tools in every request would quickly exhaust the context window, so the system must dynamically filter tools and only provide the most relevant ones.
Streaming Responses
Streaming responses are critical for a good user experience. Instead of waiting for the full response, tokens must be streamed to the client as soon as they are generated.
Multiple LLM Providers
The system should not be tightly coupled to a single model provider. Supporting multiple providers gives flexibility as the AI ecosystem evolves.
Context Window Management
Conversations can grow large very quickly. The system must summarize older conversation segments when the context window becomes too large.
Storing Conversation History
To persist conversations we maintain our own database rather than relying on model providers. This avoids vendor lock-in and gives us full control over conversation state.
Given the fast-evolving AI ecosystem, we chose MongoDB to retain flexibility in how our data models evolve.
There are two common approaches to storing conversation interactions.
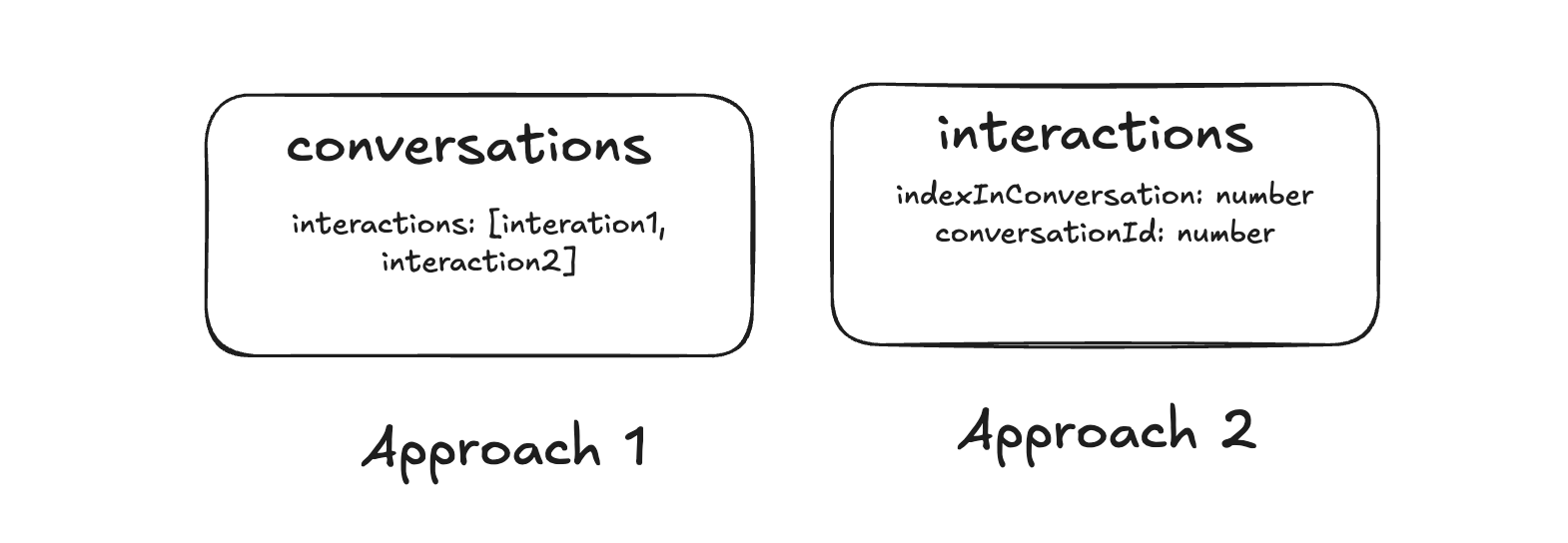
Approach 1: Array of messages
The conversation document contains an array of interaction ids.
Conversation
interactions: ["interaction-id-1", "interaction-id-2"]At Postman we have seen that storing arrays in database columns can cause issues as you scale. The underlying problem is that databases themselves don't provide any guarantees around arrays — for example if an interaction gets deleted, the onus is on the application developer to always update the array in conversation to delete that interaction.
Approach 2: Interaction records
Instead of storing messages in an array, at Postman we use an approach where each interaction contains an indexInConversation field that determines its position.
Interaction
id
conversationId
role
content
indexInConversationThis design makes updates easier. For example, inserting a message between two existing interactions can be done by assigning a fractional index:
newIndex = (previousIndex + nextIndex) / 2This avoids expensive document rewrites while maintaining ordering.
Supporting Multiple LLM Providers
The AI ecosystem evolves rapidly, and new models appear frequently. To avoid tight coupling to any single provider, the Agent Mode Service supports multiple LLM backends.
We use Portkey as a gateway to route requests across providers and maintain observability into model usage and performance.
However, different providers expose slightly different streaming formats and APIs. To normalize these differences we rely on Vercel's AI SDK, which provides a consistent abstraction layer for streaming responses across models.
This allows us to switch providers without large changes to the application code.
Tool Filtering with a Root–Sub Agent Architecture
One of the biggest challenges in building agent systems is managing large toolsets.
Agent Mode currently exposes 150+ tools that can perform actions across the Postman platform. Sending all tools to the LLM for every prompt will make it hard to manage context window.
To address this we use a two-stage agent architecture.
Root Agent
The root agent first analyzes the user prompt and generates several tool search phrases describing the task.
For example, if a user asks: Create a collection and add a request to it
The root agent might generate search phrases like:
- "create collection"
- "add request to collection"
- "postman collection tools"
Tool Retrieval
These phrases are then used to perform retrieval across the entire tool catalog.
We use a RAG-based search over tool descriptions to identify the most relevant tools. We use Turbopuffer to power this RAG search and store the embedding vectors for each tool's description.
From the full set of 150+ tools, the system selects the top 12 tools most relevant to the request.
Execution Agent
Only these filtered tools are then passed to the execution agent along with the prompt.
This significantly reduces token usage while improving the agent's ability to select the correct tool.
Managing Long Conversations
As conversations grow, the context window can become a limiting factor.
To manage this, older portions of the conversation can be summarized and replaced with compact summaries before sending the context to the LLM. This allows the system to retain conversational continuity while keeping token usage under control.
Closing Thoughts
As the AI ecosystem evolves fast, the biggest feature of this architecture is evolvability. An amazing user experience is our ultimate goal with every technical decision.